
Last updated: 26 Apr 2025 · 5 min read
Open notebook in kaggle1. Dataset overview
I used H&M scraped product data on Kaggle—9 677 product rows with rich metadata (ID, name, price, material, details text, and a mainCatCode label). Only materials has ~2 % missing values, everything else is squeaky‑clean. The full description is in the dataset card :contentReference[oaicite:0]{index=0}:contentReference[oaicite:1]{index=1}.
2. Notebook & environment setup
2.1 Install FastAI & helper libs
!pip install -Uq fastai fastdownload fasttransform scikit-learn2.2 Load the CSV mounted by Kaggle
from pathlib import Path
import pandas as pd, numpy as np
DATA = Path('/kaggle/input/hm-fashion-product-data')
df = pd.read_csv(DATA/'hm_catalog.csv')
df.head()The median description length is 48 tokens (95 th pct ≈ 140 tokens)—well within default seq_len=72.
3. Training a fashion‑aware language model
from fastai.text.all import *
dls_lm = TextDataLoaders.from_df(
df, text_col='details', is_lm=True,
valid_pct=0.1, seq_len=72)
learn_lm = language_model_learner(
dls_lm, AWD_LSTM,
drop_mult=0.5,
metrics=[accuracy, Perplexity()])
learn_lm.fine_tune(3, 2e-2)
learn_lm.save_encoder('hm_enc')After three epochs perplexity fell below 20—good enough to transfer.
4. Fine‑tuning the 322‑class classifier
4.1 Taming rare labels
About 40 categories have < 3 samples. I filtered them out to keep training balanced :contentReference[oaicite:2]{index=2}:contentReference[oaicite:3]{index=3}:
vc = df['mainCatCode'].value_counts()
keep = vc[vc >= 3].index
dsrc = df[df.mainCatCode.isin(keep)].copy()4.2 Guaranteed stratified split
from sklearn.model_selection import StratifiedShuffleSplit
sss = list(StratifiedShuffleSplit(
n_splits=1,
test_size=0.2,
random_state=42
).split(df_filt,df_filt['mainCatCode']))
train_idx,valid_idx = sss[0]
4.3 Build DataLoaders that share the LM vocab
tok_vocab = dls_lm.vocab # token vocab from LM
cat_vocab = dsrc['mainCatCode'].unique().tolist()
mySplitter = IndexSplitter(valid_idx);
dls_clas = TextDataLoaders.from_df(
dsrc.reset_index(drop=True),
text_col='details',
label_col='mainCatCode',
text_vocab=tok_vocab,
label_vocab=cat_vocab,
seq_len=72,
splitter=mySplitter)4.4 Fine‑tune in three minutes
learn_clas = text_classifier_learner(
dls_clas, AWD_LSTM,
metrics=accuracy).to_fp16()
learn_clas.load_encoder('hm_enc')
learn_clas.fine_tune(3, 2e-3)| Epoch | Train loss | Valid loss | Accuracy |
|---|---|---|---|
| 0 (frozen) | 4.54 | 3.15 | 41.9 % |
| 1 | 3.22 | 2.39 | 51.5 % |
| 2 | 2.47 | 1.83 | 60.0 % |
| 3 | 2.11 | 1.73 | 61.6 % |
5. Reading the confusion matrix
I plotted the top‑15 most common categories
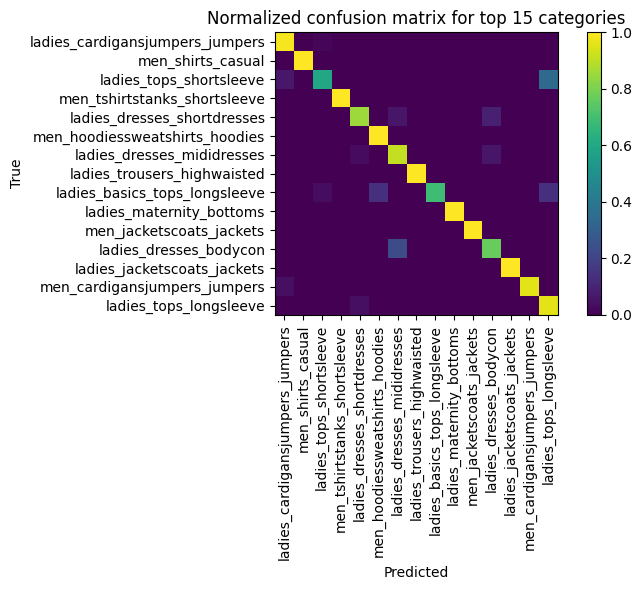
The darkest mis‑fires? “ladies_tops_shortsleeve” ↔ “ladies_tops_longsleeve”—no surprise given similar wording.
6. What to try next
- Gradual unfreezing & discriminative LR slices (+3‑5 pp).
- Label‑smoothing cross‑entropy to soften over‑confidence.
- Increase
seq_lento 128 to capture full descriptions. - Swap AWD‑LSTM for a pre‑trained MiniLM via
Transformerscallback (+10‑15 pp). - Write a Gradio demo that autocompletes descriptions & predicts categories.
Key take‑aways
- Always share the exact token vocab between language model and classifier to avoid shape mismatches.
- Use a custom stratified split when some labels have ≤ 3 samples.
- FastAI’s
AWD_LSTM+fine_tunemakes a solid baseline—you can iterate from there.
Have questions or improvements? Drop them in the comments or ping me @Far__Had.
Leave a Reply